Fight Complexity with Functional Programming
Abstract
A Metric-driven approach to reduce Cognitive Complexity in a code base, using Functional Programming, demoed hands-on, by solving a complex real-world ubiquitous design challenge - REST API Bulk Request Validation, with an extensible Framework that separates what-to-do (Validations) from how-to-do (Validation Orchestration). Let’s do a case study of a successful implementation done by our team in the world’s largest SaaS org, Salesforce.
Audience & Takeaways
-
The USP for this talk is, unlike the majority FP talks in Java/Kotlin space, which are either introductory or advanced, this has something for all levels of the audience.
- This talk starts with basic FP concepts like Imperative vs. Declarative style using Java Streams or Kotlin Sequences.
- Then the audience is gradually ramped-up towards intermediate FP concepts such as Monads, First-Class Functions , Higher-Order Functions.
- Towards the end, we touch upon concepts for an advanced audience like Function-Lifting, Dozen FP Operations for daily Programming like
foldLeftwithin the context of the problem, with pictures and simple examples. They are also provided with appropriate pointers wherever needed, to go back and refer to.
-
The audience experiences a mind-shift from the traditional mutation-heavy Imperative style to Functional style — with Immutable Objects (Using Java
Recordsor Kotlin’sData classes) and Pure-Functions (replacing Mutation with Transformation). -
With Hands-on demos, this talk adds a robust paradigm toolset and vocabulary to a programmer’s arsenal and how to apply them to simplify the modelling and designing of complex real-world problems.
-
The audience learns how to objectively perceive complexity in any codebase through metrics (measured using popular static analysis tools), and how to reduce cognitive complexity methodically.
-
Finally, we shall talk about how these concepts laid the foundation stones for our in-house open-source library Vador, a bean validation framework.
Source-Code
The concepts are language agnostic. For broader outreach, I can use either of these two for a hands-on demo:
-
Kotlin (a Modern Open-source JVM language) + Arrow (a Trending Open-source functional companion for Kotlin)
(or)
-
Java + Vavr (an Open-source functional library for Java)
As I cannot use the production code, I use code samples from my POC for the demonstration — Github repo for Java or GitHub repo for Kotlin.
The code references in this post point to the Java repo, but they can be correlated by name with the Kotlin repo.
Talk Outline
- This talk has 2 stories embedded. The first part explains the differences between Imperative and Declarative styles and demonstrates the Core:Context philosophy behind the declarative style, which helps in separating How-to-do from What-to-do, using Java Streams or Kotlin Sequences.
- Then the talk transitions to the second part with a crash course on Monads and Functional Composition.
- The second part takes the Core:Context philosophy to the next level, by applying it to solve a real-world design problem, which is common across many REST-service Domains - Batch-Validation.
- The talk demonstrates how batch-validation can quickly get complex when done imperatively, mixing what-to-do( Validations), with how-to-do(Validation Orchestration) and how it’s NOT extensible if any of these three scales - Request Batch size, Validation count and Services count.
- Then the talk offers a Functional Programming (FP) solution, using Monads and Lambdas, which Minimizes the accidental complexity without compromising Time complexity (Perf), and can seamlessly be extended.
- Throughout this talk, Simple Monads (like
Option,Either,Tryetc.,) are introduced and how they fit in the context of the problem. - This talk attempts to ramp-up the audience on functional programming gradually, and towards the end, we touch upon advanced concepts like Higher-Order Functions, Function Lifting, Dozen FP Operations for daily Programming like
foldLeftetc. - This talk is fun-filled, code-driven, and without getting into definitions (which can be read from books), the attempt is to portray hands-on experience about how FP can help us become better developers.
Introduction
With the advent of SaaS and Microservices/Macroservices, software systems majorly communicate through the network, and REST is the predominant HTTP protocol used. To reduce network latency, these services resort to Bulk-APIs. One of the significant challenges of Bulk-APIs is Request Validation. With increasing request bulk size, service routes, and the number of validations, the validation orchestration can quickly get complex when done in a traditional imperative style.
Let’s take-up a real-world problem. Our Payments-Platform domain has parallel services such as Authorization, Capture, Refund, Void. All of these are REST-APIs. They have JSON request payloads that accept sub-requests in bulk (list of JSON nodes). A simplified version of payload for one of the routes - Authorization:
[
{
"amount": 99,
"accountId": "{{validAccountId}}",
...,
"paymentMethod": {
...
},
...
},
{
"amount": 77,
"accountId": "{{validAccountId}}",
...,
"paymentMethod": {
...
},
...
}
]This JSON structure gets marshaled into POJO, which needs to be validated at the entry point of our application layer. Since all services deal with Payments, they have a lot of common fields like amount, as well as common child nodes like paymentMethod in their structure. Based on the type of field, they have different kinds of validations. E.g.:
- Data validations - to validate data integrity for fields like
amount. - Effectful validations - for fields like
accountId, which involves a DB read to verify. - Common Validations - for common fields that exist across services, such as
amount,accountId. - Nested Validations - for the member nodes like
paymentMethod. These nested members share an Aggregation/Composition relationship with their container and have validations of their own. A service in the same domain may reuse this data-structure in its payload. Such service, along with its own validations, needs to execute all the validations of this nested member.
Requirements for Validation Orchestration
Now that we talked about types of validations, let’s understand the requirements for validation orchestration (how to execute these validations).
-
Share Validations: Instead of rewriting, Share Common and Nested Validations among services that share payload structure.
-
2 Routes - 2 execution Strategies: Our database entities can be CRUD through two routes e.g., REST and SObject. They both need to be guarded with Validations. But the tricky part is - the Connect route needs to fail-fast, while the SObject needs error-accumulation.
-
Configure Validation Order for Fail-fast: A way to configure Cheaper validations first and Costlier later. Costlier validations can include Effectful validations, so we need to fail-fast and avoid unnecessary DB calls.
-
Partial failures for Batch APIs: An aggregated error response for failed sub-requests can only be sent after valid requests are processed through multiple layers of the application. We have to hold on to the invalid sub-requests till the end and skip them from processing.
-
Meta-requirements:
- Accommodate a century of validations across a domain
- Unit testability for Validations
- No compromise on Performance
Imperative treatment
We have close to 100 validations of various kinds and increasing. When the above requirements are dealt with traditional Imperative Style, it can quickly get messy, as shown here. This code is mutation filled, non-extensible, non-sharable, non-unit-testable, and difficult to reason-about.
But to state that objectively, we can run Cognitive Complexity metrics on this code, using a popular Code Quality tool called SonarQube™.
Our current imperative approach records high values for both of these metrics. (Results to be run and explained during the talk).
Need for Better Design
The 3D design problem
This problem is a 3-dimensional design problem stretching among - Sub-requests, Service routes (sharing common fields & nodes), and Validation count. In the above imperative approach, we entangled all 3, which lead to chaos. We need a design, which treats all of these separately, let them extend independently, and abstracts out validation sequencing and orchestration. We need to separate What-to-do from How-to-do.
Dichotomous Data
We have two types of data floating around throughout our validation program - Valid sub-requests and Invalid sub-requests with Validation Failures. For each sub-request, based on its state, the imperative code flow is continuously branched out with if-else and try-catch statements, which lead to much of the cognitive complexity. We need a way to represent this valid/invalid Effect so that our program flows linearly agnostic of the sub-request’s validation state.
The Bulk Validation Framework
Components
The framework mainly consists of 3 decoupled parts:
- Validations (what-to-do)
- Configuration (how-to-do)
- Orchestration (how-to-do)
Why FP?
We need an extensible framework to cater above design needs. But why is FP the best fit for solving problems like these? Every Software design problem can be seen as a block of objects doing functions or functions processing objects. We have the latter situation, where the sub-requests are being processed (validated) by various validation functions. Whenever there is a situation, where we got to apply a set of operations or transformations on a collection, where the output of a function happens to be the input for the subsequent, that’s when we should identify it’s an FP problem. Please mind, these are transformations and not Mutations.
FP is the best fit to model domains with rich business logic, filled with computations and transformations. That is the reason, it is the first choice for Machine learning, AI, BigData, Reactive Programming etc.
Immutable POJOs
Making POJOs immutable helps us take out a lot of cognitive load while reasoning about programs. Especially, when our objects are passing through an array of functions, Immutability gives a guarantee that the objects are only being Transformed and not Mutated.
With the latest Java feature Records, I shall demo how a class can be easily made immutable
Validations as Values
I used Java 8 Functional interfaces to represent the validation functions as values. Ref. This way Validation functions turn more cohesive than the imperative style, can be extended independently from each other and shared among various service routes.
Representing Effect with Either Monad
In the talk, I shall introduce Monad with a crash course and contextually explain the application of various monads, such as Option, Either, Try, Stream.
Let’s start with Either Monad - It’s a data-type container that represents the data it contains in 2 states left and right. We can leverage this Effect to represent our Dichotomous Data, where left: Validation Failure and right: Valid sub-request. Either Monad has operations (API ref) like map and flatMap, which perform operations on the contained value, only if Monad is in right state. This property helps developers write linear programs without worrying about the state of the Monad Ref.
This is a popular technique called Railway-Oriented-Programming.
Validations exchange Monad Currency
This Effect can be used as a currency to be exchanged as input-output for our independent validation functions. A validation function takes Either monad as input. If the input is in the right state, validation is performed using its API functions map or flatMap, and if the validation fails, the corresponding failure is set in the left state. Otherwise, return the monad in the right state. As long as the result of validation is in the right state, it doesn’t matter what value it has. Thus a wild-card is used in the Validator Data type signature. Ref.
The Configuration
Since functions are values, all we need is an Ordered List (like java.util.list) to maintain the sequence of validations. We can compose all the validation functions, in the order of preference. This order is Configurable easily. Ref.
However, there is a complexity. The list of Validations for a parent node consists of a mix of the parent node and child node validations. But they can’t be put under one List, as they are functions on different Data Types. So child validations need to be ported to the parent context. We can achieve this with Higher-Order Functions, which act as DSL to lift child validation to the parent type
- Ref.
This is a powerful technique, which enables us to see the code through the lens of Algebra. This way, we can configure a Chain of validations in-order, sorting out all the parent-child dependencies. This is nothing but the most popular Chain of Responsibility Design pattern, with a functional touch.
If the inter-dependencies between Parent-Child happen to be more complex, we may end up with Graph_ like relationship, but it can easily be flatten into a Chain with a simple Topological Sort_.
The Orchestration
Now we have 2 lists to intertwine - List of sub-requests to be validated against List of Validations. This orchestration can be easily achieved in many ways due to the virtue of loose coupling between What-to-do(validations) and How-to-do( Orchestration). We can switch orchestration strategies (like fail-fast strategy to error-accumulation or running validations in parallel) without affecting validations code
- Ref.
Partial failures
The partial failure sub-requests are captured as Either Monads in left state, which are passed but skipped from processing in subsequent layers, thanks to the Either Monad property we discussed above. This way these failures are ignored till the end, where they can be conveniently written to the final response as errors.
Testability
Individual validation functions are easily testable through unit-tests as they are pure and isolated. The orchestration is completely done using well-tested library functions like foldLeft, findFirst, etc. So nothing stops us from having a 100% code coverage.
Complexity
Thanks to the monad abstracting away all the branching complexity, our linear code has minimum complexity, which makes it easy to extend, debug and reason about. We can rerun the previous complexity metrics to prove it.
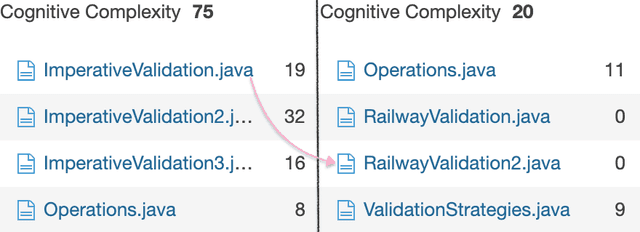 As pointed out, we can compare Imperative approach with the Declarative one. Despite the declarative implementation having more validations than imperative implementation, the Cognitive Complexity remains minimum.
As pointed out, we can compare Imperative approach with the Declarative one. Despite the declarative implementation having more validations than imperative implementation, the Cognitive Complexity remains minimum.
Conclusion
Functional Programming is not Complex, but it fights complexity. The solution runs with the same time complexity (no perf impact), but minimum cognitive complexity. The framework is generic and agnostic of programming language and can be consumed by any Service with similar requirements, with minor modifications.
My Talks on this
- 🇺🇸 All Things Open, 2020, Raleigh, USA. 📃
- 🏴 Kotlin User Group, London
- 🇩🇪 Berlin Functional Programming Group
- 🇳🇴 JavaBin, Norway
- 🇩🇪 Kotlin User Group, Berlin
- 🇮🇳 Google Developer Group Devfest 2019
- 🇮🇳 Java User Group Hyderabad (@JUGHyd)
- 🇮🇳 Salesforce, Hyderabad, India
- 🇮🇳 Kotlin User Group, Hyderabad
Kotlin Version
-
The Slide-deck
-
Source-code links:
10-2020 (All Things Open, Raleigh, USA)
09-2020 (Kotlin User Group, London)
04-2020 (Kotlin User Group, Berlin)
05-2020 (Kotlin User Group, Hyderabad)
Java Version
-
The Slide-deck
-
Source-code links:
06-2020 (Berlin FP Group, Germany)
05-2020 (JavaBin, Norway)
08-2019 (Salesforce, Hyderabad)